Watershed segmentation
This example demonstrates how to perform watershed segmentation.
In pi2, you will have to first generate seeds image that contains colored regions that will be grown in the watershed process. The filling priority of pixels must also be calculated somehow, usually this is the gradient of the input image, but in this example we use the input image itself.
def watershed():
"""
Demonstrates Meyer's flooding algorithm for calculation of watershed.
"""
# Read image
weights = pi.read(input_file('t1-head.tif'))
# Create new image, taking unspecified properties from the old image
labels = pi.newlike(weights, 'uint8')
# Set some seeds
pi.set(labels, [110, 90, 63], 100) # Brain
pi.set(labels, [182, 165, 63], 200) # Skull
# Save seeds so that they can be viewed later
pi.writetif(labels, output_file('meyer_grow_seeds'))
# Grow the seeds. (Normally you would use gradient of input image etc. as weight)
pi.grow(labels, weights)
# Save result
pi.writetif(labels, output_file('meyer_grow'))
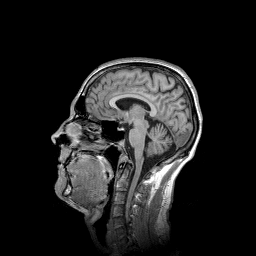
One slice of the input image.
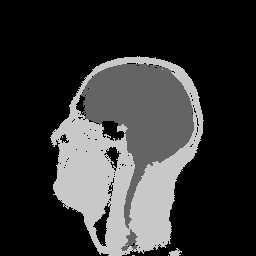
Result of watershed segmentation.